START 文
START 文は、相対ファイルまたは索引ファイル内で、後続のレコードを取得するための論理的な位置指定の基礎となる。この文は順編成ファイルでは利用できない。
![]() START 文は、スレッドの実行を同期または非同期で開始する。
START 文は、スレッドの実行を同期または非同期で開始する。
書き方 1 の一般形式 (相対ファイル)
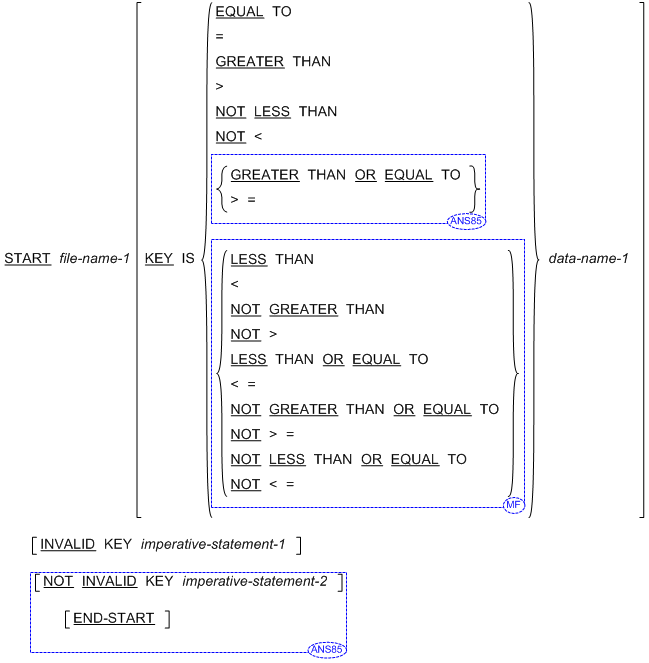
書き方 2 の一般形式 (索引ファイル)
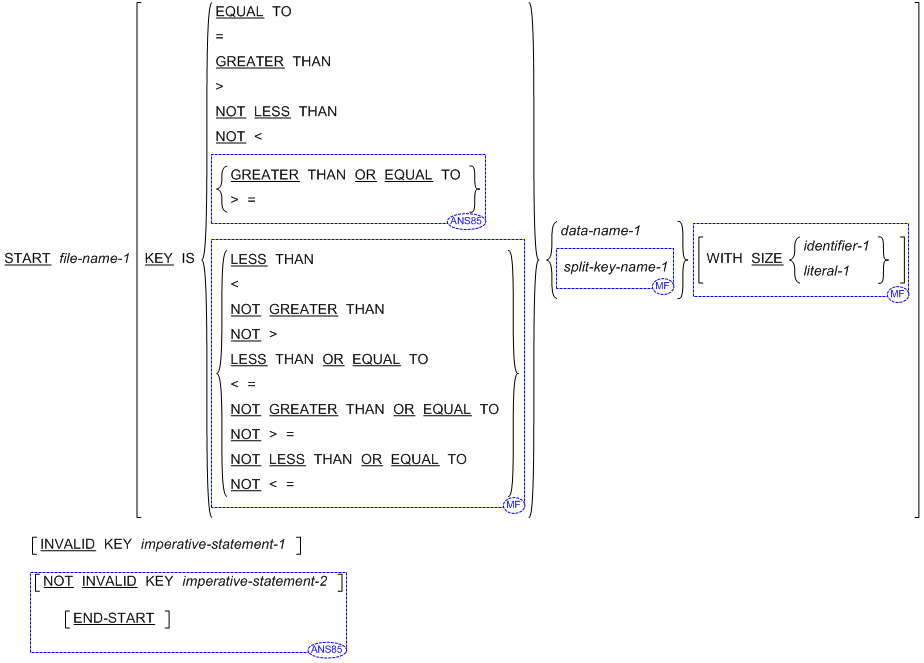
書き方 3 の一般形式 (スレッド)
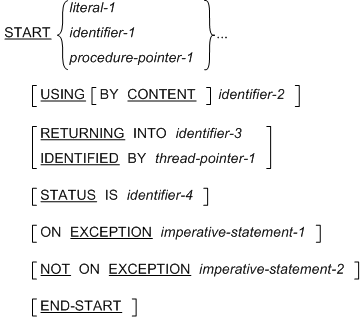
すべての書き方に関する構文規則 (相対ファイルおよび索引ファイル)
- file-name-1 は、相対ファイルまたは索引ファイルの名前とする。
- file-name-1 は、順呼び出し法または動的呼び出し法のファイルの名前とする。
- data-name-1 は修飾できる。
- file-name-1 に適用できる USE 手続きを指定していない場合は、INVALID KEY を指定する。

 この規則は必須ではない。
この規則は必須ではない。
- THAN の代わりに THEN も使用できる。
書き方 1 の構文規則 (相対ファイル)
- KEY を指定した場合、data-name-1 は、関連付けたファイル管理記述項の RELATIVE KEY に指定したデータ項目とする。
書き方 2 の構文規則 (索引ファイル)
- KEY を指定した場合、data-name-1 は、file-name-1 に関連付けたレコード キーとして指定したデータ項目を参照できる。data-name-1 は、file-name-1 に関連付けたレコード キーとして指定したデータ項目に属する、項類が英数字のデータ項目も参照できる。そのデータ項目の左端の文字位置は、そのレコード キー データ項目の左端の文字位置に対応する。
- split-key-name-1 は 1 つ以上のデータ項目を参照でき、file-name-1 に関連付けたレコード キーとして指定される。
- WITH SIZE は、位置決め処理で使用するキー内の文字数を指定する。
- identifier-1 は、WITH SIZE 指定を併用する場合、基本整数データ項目の名前とする。
- DIALECT"RM" 指令または DIALECT"ACU" 指令が有効な場合、KEY で指定した data-name-1 または split-key-name-1 は、それらの最後の修飾子として file-name-1 が明示的に指定されていなければ、START 文で指定した file-name-1 で暗黙的に修飾される。それ以外の方言の場合、data-name-1 または split-key-name-1 は、参照規則を一意にするために、必要に応じて file-name-1 を最後の修飾子として明示的に指定する。
書き方 3 の構文規則 (スレッド)
- literal-1 は文字定数とする。表意定数は指定できない。
- identifier-1 は英数字データ項目として定義し、その値が COBOL のプログラム名でも COBOL 以外のプログラム名でもよいようにする。
- identifier-3 は、USAGE POINTER として定義するか、サイズが 4 バイトのデータ項目とする。この定義は、新しいスレッドの EXIT PROGRAM または STOP RUN 文内の GIVING または RETURNING
項目の定義に依存する。identifier-3 を USAGE POINTER 項目として定義する場合、関数一意名であってはならない。
- thread-pointer-1 は USAGE THREAD-POINTER として定義する。
- identifier-4 は、長さが 4 桁以上の整数データ項目として定義する。
すべての書き方に関する一般規則 (すべてのファイル)
- file-name-1 は、START 文を実行する際には、入力モードまたは入出力両用モードで開いておく。「OPEN 文」トピックを参照。
- KEY を指定しない場合、比較演算 IS EQUAL TO が暗黙指定される。
- START 文を実行すると、file-name-1 に関連付けた FILE STATUS データ項目の値 (指定した場合) が更新される。「手続き部」の章の「入出力状態」のトピックを参照。
- START 文がレコード ロックを取得、検出、または解除することはない。
書き方 1 の一般規則 (相対ファイル)
- KEY 指定内の比較演算子が指定する比較のタイプは、file-name-1 が参照するファイル内のレコードに関連付けたキーと、一般規則 6 で指定したデータ項目との間で行われる。
 比較演算子で、キーをデータ項目と等しいか、より大きいか、以上と指定すると、
比較演算子で、キーをデータ項目と等しいか、より大きいか、以上と指定すると、
ファイル内にある論理レコードのうち、キーがその比較条件を満たす最初のレコードに、ファイル位置指示子が位置指定される。
-
比較演算子で、キーをデータ項目より小さいか、以下と指定すると、ファイル内にある論理レコードのうち、キーがその比較条件を満たす最後のレコードに、ファイル位置指示子が位置指定される。
- 比較条件を満たすレコードがファイル内にない場合、INVALID KEY 条件が発生する。この場合、START 文の実行は失敗し、ファイル位置指示子の内容は不定となる。「手続き部」の章の「INVALID KEY 条件」トピックを参照。
- 一般規則 5 に記載の比較では、file-name-1 に関連付けた RECORD KEY 句が参照するデータ項目を使用する。RELATIVE KEY 句は、file-name-1 に関連付ける。
書き方 2 の一般規則 (索引ファイル)
- KEY 指定内の比較演算子が指定する比較のタイプは、file-name-1 が参照するファイル内のレコードに関連付けたキーと、一般規則 8 で指定したデータ項目との間で行われる。file-name-1 が索引ファイルを参照し、各作用対象のサイズが異なる場合、サイズが長い方の作用対象の右端が切り捨てられて、サイズが短い方の作用対象と長さが等しいかのように比較処理が進行する。文字の比較に関するその他の規則が、すべてこの比較に適用される。ただし、PROGRAM
COLLATING SEQUENCE 句は、この比較には効力をもたない。「手続き部」の章の「比較条件」セクションの「文字作用対象の比較」トピックを参照。
- 比較演算子で、キーをデータ項目と等しいか、より大きいか、以上と指定すると、
ファイル内にある論理レコードのうち、キーがその比較条件を満たす最初のレコードに、ファイル位置指示子が位置指定される。
- 比較演算子で、キーをデータ項目より小さいか、以下と指定すると、ファイル内にある論理レコードのうち、キーがその比較条件を満たす最後のレコードに、ファイル位置指示子が位置指定される。このキーが重複する記述項を持つ場合、そのうちの最後の記述項にファイル位置指示子が位置指定される。
- 比較条件を満たすレコードがファイル内にない場合、INVALID KEY 条件が発生する。この場合、START 文の実行は失敗し、ファイル位置指示子の内容は不定となる。「手続き部」の章の「INVALID KEY 条件」トピックを参照。
- KEY を指定した場合、一般規則 7 に記載の比較では、data-name が参照するデータ項目を使用する。
- KEY を指定しない場合、一般規則 7 に記載の比較では、file-name-1 に関連付けた RECORD KEY 句で参照するデータ項目を使用する。
-
START 文の実行が成功した後、以下のように参照キーが設定され、後続の書き方 3 の READ 文で使用される (「READ 文」トピック参照)。
- KEY を指定しない場合、file-name-1 に指定した主レコード キーが参照キーとなる。
- KEY を指定し、file-name-1 のレコード キーとして data-name-1
または split-key-name-1
を指定した場合、そのレコード キーが参照キーとなる。
- KEY を指定し、file-name-1 のレコード キーとして data-name-1
または split-key-name-1
を指定しなかった場合は、data-name-1
または split-key-name-1
で指定した項目の左端の文字位置が同じであるレコード キーが参照キーとなる。
- START 文の実行が失敗した場合、参照キーは不定となる。
書き方 3 の一般規則 (スレッド)
- literal-1、identifier-1、または procedure-pointer-1 はプログラム名を参照するものとする。このプログラム名は、翻訳単位の最外部のプログラム名、プログラム内のエントリ ポイント、または別の言語のラベルのいずれかになる。これは、新しく作成したスレッドの実行開始点となる。
- identifier-2 を指定した場合、新しく作成したスレッドの開始点は、参照によって渡される単一のパラメーターを受け入れるように定義する必要がある。
- BY CONTENT を指定した場合、identifier-2 の内容はシステムが割り当てたスレッド セーフな作業領域にコピーされ、この作業領域への参照は新しく作成したスレッドの開始点に渡される。この作業領域は、作成したスレッドの実行中は常に有効であり、作成元プログラムのデータ領域の有効期間には関係ない。
- BY CONTENT を指定しない場合、identifier-2 への直接参照は、新しく作成したスレッドの開始点に渡される。新しく作成したスレッドがデータ領域を参照している間は、そのデータ領域が有効であるようにする必要がある。
- RETURNING を指定した場合、新しく作成したスレッドは完了するまで実行され、identifier-3 の値を返し、制御を START 文に戻す。
- IDENTIFIED BY を指定した場合、新しく作成したスレッドの実行が開始され、そのスレッドを参照するハンドルが thread-pointer-1 に配置され、START 文に制御が戻る。このハンドルは WAIT 文で使用でき、返却値を取得し、実行を同期して、スレッドのリソースを解放する。このハンドルは、CBL_THREAD_
ライブラリ ルーチンで使用される有効なスレッド ハンドルである。
- RETURNING も IDENTIFIED も指定しない場合は、新しく作成したスレッドが開始され、START 文に制御が戻る。スレッドの終了時に、そのスレッドのすべてのリソースが自動的に解放される。
- STATUS 指定が記述されている場合、START 文の実行により、CBL_THREAD_ ライブラリ ルーチンに対して指定された戻りコードのいずれかが identifier-4 に格納される。
- START 文が失敗した場合、CBL_THREAD_ ライブラリ ルーチンに指定した戻りコードのいずれかが identifier-4 に格納され (指定した場合)、以下の処理のいずれかが実行される。
- ON EXCEPTION を指定した場合、制御が imperative-statement-1 に移る。その後、imperative-statement-1 で指定した各文に関する規則に従って、処理が継続する。制御を明示的に移す手続き分岐文または条件文を実行すると、その文の規則に従って制御が移る。それ以外の場合で、imperative-statement-1 の実行が完了すると、制御は START 文の末尾に移り、NOT ON EXCEPTION は指定されていても無視される。
- それ以外の場合で、NOT ON EXCEPTION または STATUS が指定されていると、制御は START 文の末尾に移り、NOT ON EXCEPTION は指定されていても無視される。
- 上記以外の場合、実行時システム エラーが発生して実行単位が終了する。
- START 文が成功した場合は、以下の処理が指定された順に実行される。
- STATUS を指定した場合、ゼロが identifier-4 に格納される。
- NOT ON EXCEPTION を指定した場合、制御が imperative-statement-2 に移る。その後、imperative-statement-2 で指定した各文に関する規則に従って、処理が継続する。制御を明示的に移す手続き分岐文または条件文を実行すると、その文の規則に従って制御が移る。それ以外の場合で、imperative-statement-2 の実行が完了すると、制御は START 文の末尾に移り、ON EXCEPTION は指定されていても無視される。