REPLACE 文
書き方 1 の一般形式
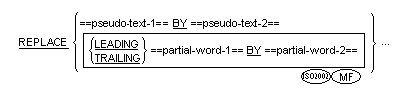
書き方 2 の一般形式
構文規則
- REPLACE 文は、ソース原文または登録集原文内で、文字列または分離符 (定数の終了区切り文字を除く) を記述できる任意の場所で指定できる。REPLACE 文が翻訳群内の最初の文でない場合は、REPLACE 文の前に分離符のスペースを記述する。
- REPLACE 文は、分離符の終止符 (ピリオド) で終了する。
- pseudo-text-1 には、1 つ以上の原文語を含める。
- pseudo-text-2 には、1 つ以上の原文語を含める (含めなくてもよい)。
- pseudo-text-1 および pseudo-text-2 内の文字列は、次の行へ継続できる。
- pseudo-text 内の原文語の文字数は、1 文字から 322 文字までとする。
- pseudo-text-1 を、分離符のカンマまたはセミコロンだけで構成することはできない。
- 語 REPLACE が注記項内または注記項を記述できる場所にある場合、REPLACE は注記項の一部と見なされる。

 partial-word-1 は、1 つの原文語で構成する。
partial-word-1 は、1 つの原文語で構成する。
- partial-word-2 は、1 つの原文語で構成する (省略も可能)。
- partial-word-1 および partial-word-2 には、文字定数および各国文字定数を指定できない。
一般規則
- pseudo-text-1 には、pseudo-text-2 によって置換されるソース原文を指定する。
- partial-word-1 には、partial-word-2 によって置換される原文を指定する。
- 書き方 2 の REPLACE 文は、現在有効な原文置換を中止することを指定する。
- REPLACE 文の効力は、指定した時点から、次の REPLACE 文の登場箇所まで、または翻訳単位の終了時まで持続する。
- ソース単位に含まれる REPLACE 文の処理は、そのソース単位に含まれる COPY 文 (ある場合) の処理後に行われる。
- REPLACE 文の処理結果として生成された原文には、COPY 文および REPLACE 文は含められない。
- 原文置換を決定する比較操作は、REPLACE 文の直後の原文から始まり、次のように行われる。
- 左端のソース原文語および最初の pseudo-text-1 または partial-word-1 で始まり、pseudo-text-1 または partial-word-1 が、連続する同数のソース原文語と比較される。
- pseudo-text-1 がソース原文と一致するのは、pseudo-text-1 を構成する原文語の順番が、ソース原文語の順番と同じである場合のみである。
LEADING を指定すると、partial-word-1 がソース原文語と一致するのは、partial-word-1 を構成する一連の順序の文字列が、そのソース原文語の左端の文字位置から開始する同数の連続する文字列と一字一句同じである場合のみとなる。TRAILING
を指定すると、partial-word-1 がソース原文語と一致するのは、partial-word-1 を構成する一連の順序の文字列が、そのソース原文語の右端の文字位置で終了する同数の連続する文字列と一字一句同じである場合のみとなる。
- 一致処理では次の規則が適用される。
- pseudo-text-1 またはソース原文内では、分離符のカンマ、セミコロン、または空白の登場箇所はすべて単一の空白と見なされる。1 つ以上の空白の分離符は、単一の空白と見なされる。
- 各小文字は、COBOL 文字集合に指定されている対応する大文字と等しい。ただし、文字定数または各国文字定数で使用されている場合は除く。
- デバッグ行内の原文語は、「D」が指示子領域にない場合と同様に一致処理の対象となる。
 連結式の各作用対象および演算子は、別個の原文語である。
連結式の各作用対象および演算子は、別個の原文語である。
- 照合結果が一致しなかった場合、後続の各 pseudo-text-1 または partial-word-1 を対象として比較が繰り返される。この比較処理は、一致するものを検出するまで、または後続の pseudo-text-1 または partial-word-1 がなくなるまで続行する。
- pseudo-text-1 または partial-word-1 のすべての登場箇所を比較しても、一致するものが検出されなかった場合、次の連続するソース原文語は、左端のソース原文語と見なされ、pseudo-text-1 または partial-word-1 の最初の登場箇所で比較サイクルが再開する。
- pseudo-text-1 およびソース原文との間で比較結果が一致した場合、対応する pseudo-text-2 がソース原文内の一致した原文を置換する。
partial-word-1 およびソース原文語との間で比較結果が一致した場合、partial-word-2 がゼロの原文語で構成されていると、そのソース原文語の一致文字が partial-word-2 に置き換えられるか、削除される。
比較の対象のソース原文語部分のうち、右端の原文語の直後の語が、左端のソース原文語であると見なされる。比較サイクルが、pseudo-text-1 または partial-word-1 の最初の登場箇所から再開する。
- 比較処理は、REPLACE 文の範囲内のソース原文の右端の原文語が、一致処理に入るまで、または左端のソース原文語と見なされて比較サイクルを完了するまで継続する。
- ソース原文または pseudo-text-1 内の注記行または空白行は、一致比較を行う場合は無視される。ソース原文および pseudo-text-1 内の原文語の順序は、正書法に関する規則に従って決まる。詳細については、「言語の基礎」の章の「正書法の表現」トピックを参照。pseudo-text-2 の注記行または空白行は、テキスト置換の結果として pseudo-text-2 がソース原文に挿入されるたびに、結果のソース原文にそのまま配置される。ソース原文内の注記行または空白行が、pseudo-text-1 に一致する一連の原文語内にある場合、それらは結果のソース原文には挿入されない。
- 残りのソース コードの構文を検証できるのは、すべての COPY 文および REPLACE 文の処理が完了した後のみである。
- REPLACE 文の処理結果としてソース原文に挿入される原文語は、正書法に関する規則に従ってソース原文内に配置される。詳細については、「言語の基礎」の章の「正書法」トピックを参照。pseudo-text-2 の原文語をソース原文に挿入する際に、空白を追加できるのは、すでに空白がある原文語同士の間のみである (ソース行同士の間に想定される空白を含む)。
- REPLACE 文の処理結果としてソース原文に行が追加される場合、追加される行の標識領域には置換される原文が開始する行と同じ文字が配置される。ただし、置換される行がハイフン (-) を含む場合は、空白が配置される。
pseudo-text-2 内の定数が、結果のソース原文で行送りをしなければ 1 行に収まりきらないほど長く、かつその定数をデバッグ行に配置しているのでない場合、あふれる分を格納する継続行が追加される。置換した結果、定数の続きがデバッグ行にかかる場合、翻訳単位はエラーとなる。
- REPLACE が有効なソース原文には、EXEC HTML 文は含められない。この規則に違反すると、予期しない動作および構文エラーが発生する可能性がある。